
MASt3R: Transformer-Based Image Matching and 3D Reconstruction
Introduction 🔍
After countless hours struggling with COLMAP, manual calibration, and missing camera metadata, discovering MASt3R was a game-changer.
Developed by NAVER Labs Europe, MASt3R (Matching and Stereo 3D Reconstruction) builds on the DUSt3R pipeline and adds a transformer-based image matcher and stereo reconstruction model that performs impressively well — even with no camera pose information.
I first discovered it while working on the GaussianObject project, which relied on MASt3R for COLMAP-free pose estimation. The results led me to explore the full potential of the MASt3R pipeline.
About MASt3R 📄
MASt3R – Matching And Stereo 3D Reconstruction
Project page | GitHub | Paper
MASt3R enhances DUSt3R by adding a new matching head and a dense local feature map generator. These upgrades enable:
- Metric 3D reconstruction with high accuracy
- Dense local feature extraction
- Scalability to thousands of images
- Strong performance in map-free localization
It has shown exceptional results on benchmarks for 3D reconstruction, localization, and stereo depth estimation — particularly in settings where no prior map or pose is available.
How MASt3R Works 🧠
At the core of MASt3R is a transformer-based architecture designed for dense image matching and stereo reconstruction. Transformers, originally used for natural language processing, have transformed vision tasks by capturing long-range spatial dependencies between image regions.
MASt3R builds upon DUSt3R’s use of pointmap regression, where it predicts 3D point correspondences across image pairs. It adds:
- A dense feature head trained for local consistency across images
- A matching loss to enhance pixel-level correspondence
- A reciprocal matching algorithm that’s both fast and theoretically grounded
This makes MASt3R far more robust than traditional 2D matchers, particularly under large viewpoint changes. It outperforms other models in map-free localization benchmarks — cutting translation error by a third and rotation error by 80%.
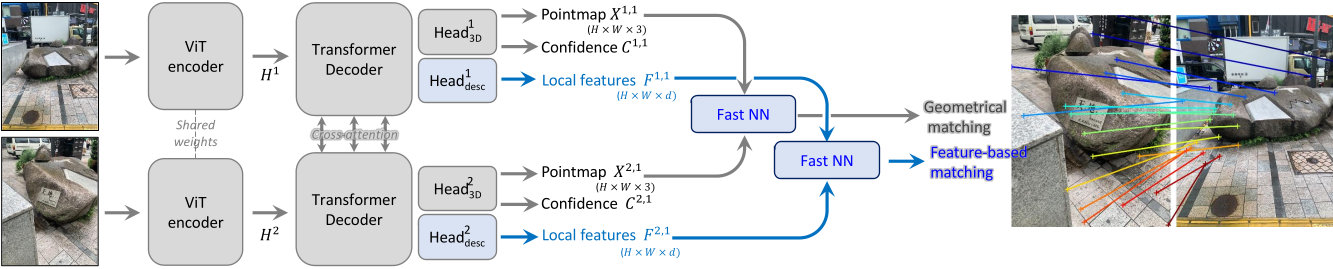
Why It Stands Out 💡
- No camera poses required
- Handles large image sets (hundreds to thousands of images)
- Extremely low localization error: 0.36 translation, 2.2° rotation
- Performs metric-scale 3D reconstruction
- Works well with real-world, casually captured imagery
It’s especially promising for applications in robotics, AR/VR, mapping, and localization in previously unseen environments.
Installation & Setup ⚙️
I tested MASt3R both locally and on Hugging Face’s demo:
🔧 Setup
# Clone with submodules
git clone --recursive https://github.com/naver/mast3r
cd mast3r
# Set up environment
conda create -n mast3r python=3.11 cmake=3.14.0
conda activate mast3r
# Install PyTorch + CUDA
conda install pytorch torchvision pytorch-cuda=12.1 -c pytorch -c nvidia
# Install dependencies
pip install -r requirements.txt
pip install -r dust3r/requirements.txt
pip install -r dust3r/requirements_optional.txt
# Compile RoPE CUDA kernels (optional for speed)
cd dust3r/croco/models/curope/
python setup.py build_ext --inplace
cd ../../../../
Checkpoints 📦
You can download pretrained models from:
mkdir -p checkpoints/
wget https://download.europe.naverlabs.com/ComputerVision/MASt3R/MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric.pth -P checkpoints/
Or use the integrated Hugging Face hub — weights download automatically during inference.
Real-World Results 🧪
I tested MASt3R on several image sets — ranging from posed datasets to casual captures.
- Even without any camera metadata, MASt3R successfully reconstructed sparse point clouds.
- Compared to classical COLMAP workflows, MASt3R delivered better results — especially for real-world images with poor lighting, reflections, or inconsistent angles.
- The generated pose estimations also worked well as input to GaussianObject, improving its reconstruction quality even further.
Related Work & Reference
If you’re interested in the technical details, here’s the paper that explains MASt3R’s innovations:
Grounding Image Matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, Jérôme Revaud
arXiv:2406.09756
Also check out:
- DUSt3R – the original framework MASt3R builds on
- Camenduru’s Jupyter notebook implementation – very useful for experimentation
What’s Next? 🚀
While I’m really impressed with MASt3R, my experiments with the retrieval-based MASt3R-SfM variant delivered even better results — especially in sparse, unstructured real-world scenes.
I’ve written a follow-up project page for MASt3R-SfM, where I share the pipeline, setup, and evaluation.
📝 You can also check out my GaussianObject post which uses MASt3R in its COLMAP-free pipeline.
TL;DR Summary
- MASt3R is a transformer-based stereo matching & 3D reconstruction model
- Handles large, pose-free image sets
- Produces accurate depth and pose estimates
- Outperforms classical SfM/MVS pipelines
- A major step forward for real-world 3D vision tasks
Stay tuned for the next post on MASt3R-SfM 👀